嘉宾简介

李文耀 全局光照利器CloudGI技术全解析
2011年加入网易,天下事业部程序设计专家,网易金牌讲师。目前主要从事天下引擎渲染模块设计开发,成功研发秒级别烘培软件CloudGI。
分享内容
文字实录
全局光照利器CloudGI技术全解析
1/30
-
 手游有一个非常有趣的现象,就是市面上所有的3D手游都选择同一种光照技术――烘焙。烘焙是非常直接也非常古老的技术,它的基本思想就是静态的灯光与静态的物质之间的光照结果是确定不变的,我们可以事先计算起来,保存成一张贴图。由于渲染效率非常高,大部分的手游都会用这个方法。剩下的问题是我们如何高效的生产这张光照贴图,我们如何把3小时的烘焙时间缩短到10秒,怎么把烘焙时间加速1000倍。
手游有一个非常有趣的现象,就是市面上所有的3D手游都选择同一种光照技术――烘焙。烘焙是非常直接也非常古老的技术,它的基本思想就是静态的灯光与静态的物质之间的光照结果是确定不变的,我们可以事先计算起来,保存成一张贴图。由于渲染效率非常高,大部分的手游都会用这个方法。剩下的问题是我们如何高效的生产这张光照贴图,我们如何把3小时的烘焙时间缩短到10秒,怎么把烘焙时间加速1000倍。
-
 今天我有三个内容的分享。第一,烘焙是什么?如果要用烘焙,项目中不同的成员要做什么样的准备。第二,我们如何在1秒中内算完成百上千盏灯光的光照和阴影的效果。最后一个是我们核心的价值,就是10秒钟内算完一千万点云之间的间接光照,这是什么概念?传统游戏做实时渲染时,我们只算灯光跟物体直接的光照作用,而实际上现实中光照会反弹,进而影响周围的物体的光线,而且这个反弹会进行多次反射,这一部分的计算量非常大,是一个指数增长的规模。我们如何把指数级别的增长降低到线性增长,3小时怎么缩短到10秒?
今天我有三个内容的分享。第一,烘焙是什么?如果要用烘焙,项目中不同的成员要做什么样的准备。第二,我们如何在1秒中内算完成百上千盏灯光的光照和阴影的效果。最后一个是我们核心的价值,就是10秒钟内算完一千万点云之间的间接光照,这是什么概念?传统游戏做实时渲染时,我们只算灯光跟物体直接的光照作用,而实际上现实中光照会反弹,进而影响周围的物体的光线,而且这个反弹会进行多次反射,这一部分的计算量非常大,是一个指数增长的规模。我们如何把指数级别的增长降低到线性增长,3小时怎么缩短到10秒?
-
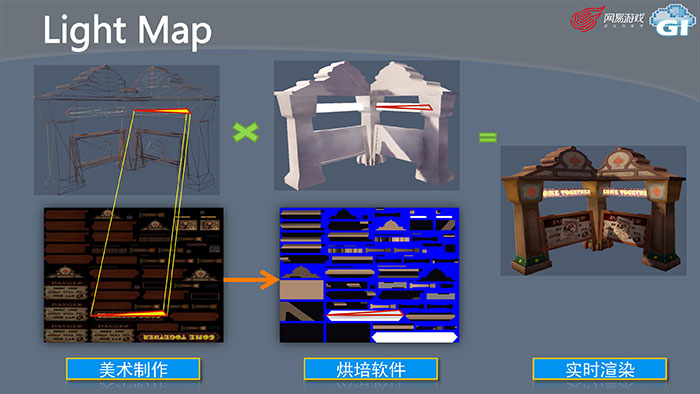 我们首先来看如果一个项目要用烘焙,要做哪些事情?对于每一个模型,首先美术要把模型的每一个三角面片不重叠地展开到一个UV空间里。为什么不直接用材质UV呢?因为材质UV上往往为了省贴图,会做镜像或者复用。但是光照贴图由于每个面上的光照结果都是不一样的,所以不能复用,需要重新创造一层贴图。第二个步骤是我们根据UV空间,烘焙一张与之对应的光照贴图,这是烘焙软件做的工作。这个贴图看起来有一点奇怪,我们映射回3D模型,就可以看到基本的光照结果。最后实时渲染的时候,项目组的程序去写Shader就非常简单了,只要把美术制作的部分和烘焙后的贴图相结合就可以得到最终的渲染效果了,这样的效率非常高。
我们首先来看如果一个项目要用烘焙,要做哪些事情?对于每一个模型,首先美术要把模型的每一个三角面片不重叠地展开到一个UV空间里。为什么不直接用材质UV呢?因为材质UV上往往为了省贴图,会做镜像或者复用。但是光照贴图由于每个面上的光照结果都是不一样的,所以不能复用,需要重新创造一层贴图。第二个步骤是我们根据UV空间,烘焙一张与之对应的光照贴图,这是烘焙软件做的工作。这个贴图看起来有一点奇怪,我们映射回3D模型,就可以看到基本的光照结果。最后实时渲染的时候,项目组的程序去写Shader就非常简单了,只要把美术制作的部分和烘焙后的贴图相结合就可以得到最终的渲染效果了,这样的效率非常高。
-
 我们直接光照是怎么做的?首先讲一下CloudGl引擎的架构图。其次,直接光照没有大家想象得那么简单,还有一些比较难理解的问题。最后说一下我们如何解决Lightmap裂缝问题。
我们直接光照是怎么做的?首先讲一下CloudGl引擎的架构图。其次,直接光照没有大家想象得那么简单,还有一些比较难理解的问题。最后说一下我们如何解决Lightmap裂缝问题。
-
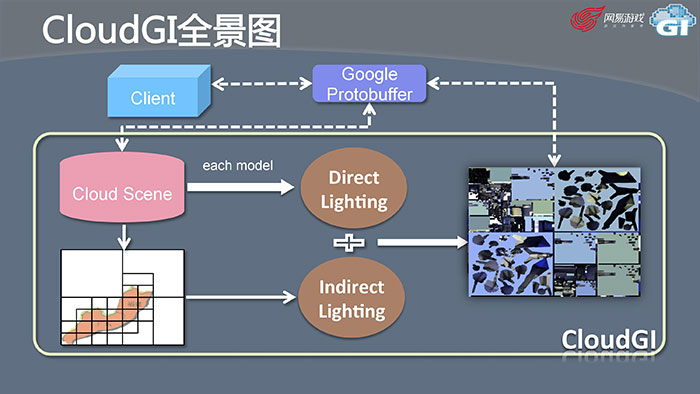 CloudGl其实是一个独立的进程,相当于一个服务端,客户端通过Google Protobuffer和CloudGI进行数据同步。数据传过来后我们称之为Cloud Scene。为了加速,我们把Scene做一个Octree(八叉树)展开。Scene里面的每一个模型进行一次直接的光照,对Octree进行间接光照处理后整合起来得到最后的光照贴图light map,最后把光照贴图重新发回客户端,这样就完成了整个工作流程。
CloudGl其实是一个独立的进程,相当于一个服务端,客户端通过Google Protobuffer和CloudGI进行数据同步。数据传过来后我们称之为Cloud Scene。为了加速,我们把Scene做一个Octree(八叉树)展开。Scene里面的每一个模型进行一次直接的光照,对Octree进行间接光照处理后整合起来得到最后的光照贴图light map,最后把光照贴图重新发回客户端,这样就完成了整个工作流程。
-
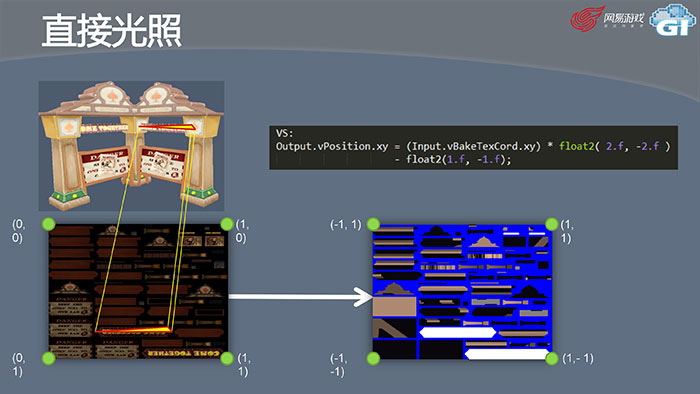 然后我们看一下直接光照怎么做?传统的做法是在CPU上做,对每一个模型的每个面片进行模拟光照化,再对整个场景进行光照,这里需要巨量的运算时间。其实做光照对显卡来说是非常方便的事情,我们可以利用现在强大的GPU做这个事情。
然后我们看一下直接光照怎么做?传统的做法是在CPU上做,对每一个模型的每个面片进行模拟光照化,再对整个场景进行光照,这里需要巨量的运算时间。其实做光照对显卡来说是非常方便的事情,我们可以利用现在强大的GPU做这个事情。
-
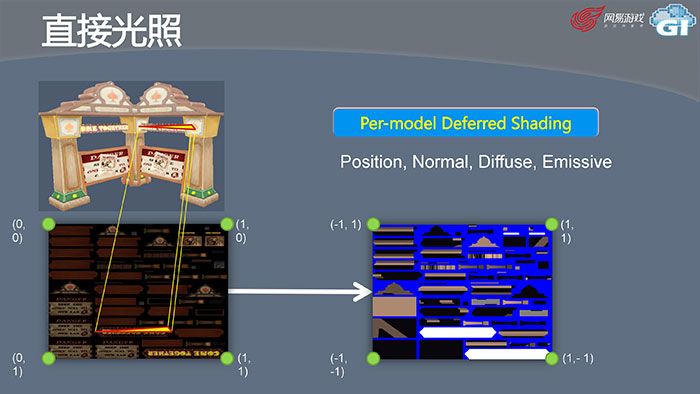 虽然已经可以进行光照了,但如果这个场景里有100盏投射阴影的点光源时,不管哪一种光照模型,没办法同时做100盏灯光阴影的计算。我们用一种方法叫Per-model Deferred Shading,可以做任一灯光阴影。听起来很耗时,实际上很快,因为虽然场景有100盏灯光,但对某个物体真正作用的只是它周围的那几盏。
虽然已经可以进行光照了,但如果这个场景里有100盏投射阴影的点光源时,不管哪一种光照模型,没办法同时做100盏灯光阴影的计算。我们用一种方法叫Per-model Deferred Shading,可以做任一灯光阴影。听起来很耗时,实际上很快,因为虽然场景有100盏灯光,但对某个物体真正作用的只是它周围的那几盏。
-
 我们做完直接光照,看一下烘焙出来的效果,发现有很多白白的裂缝,它是怎么产生的?
我们做完直接光照,看一下烘焙出来的效果,发现有很多白白的裂缝,它是怎么产生的?
-
 这是每一个烘焙软件都遇到的问题,因为在世界空间里面,连续的两个三角面片在UV空间里面是不连续的,这个问题怎么解决?
这是每一个烘焙软件都遇到的问题,因为在世界空间里面,连续的两个三角面片在UV空间里面是不连续的,这个问题怎么解决?
-
 标准解决办法就是Gutter,大家可以看到UV贴图上每一块都有一个安全的边距,这个边距我们叫做Gutter,也就是沟壑。我们用烘焙点颜色填充这些Gutter,问题就解决了。
标准解决办法就是Gutter,大家可以看到UV贴图上每一块都有一个安全的边距,这个边距我们叫做Gutter,也就是沟壑。我们用烘焙点颜色填充这些Gutter,问题就解决了。
-
 但是发现还是有一些亮点,这不是Gutter造成的,困扰了我们很久。
但是发现还是有一些亮点,这不是Gutter造成的,困扰了我们很久。
-
 当然,这个问题最后还是解决了。
当然,这个问题最后还是解决了。
-
 我们分析一下它产生的原因。因为总是在非常细小的边上产生这个问题,一个面片投射到UV空间里,如果面积小于一个象素,这时进行光照烘焙之后这部分就没有了,在light map上面不会留下自己的痕迹。实时渲染时,自己的颜色就会被周围Gutter制造的颜色覆盖掉,所以它会亮起来或者黑掉。我们的方法是进行Super Sample,保证至少有1个像素大小,在这个基础上进行Gutter,就能在light Map留下自己的痕迹,把这个问题解决。
我们分析一下它产生的原因。因为总是在非常细小的边上产生这个问题,一个面片投射到UV空间里,如果面积小于一个象素,这时进行光照烘焙之后这部分就没有了,在light map上面不会留下自己的痕迹。实时渲染时,自己的颜色就会被周围Gutter制造的颜色覆盖掉,所以它会亮起来或者黑掉。我们的方法是进行Super Sample,保证至少有1个像素大小,在这个基础上进行Gutter,就能在light Map留下自己的痕迹,把这个问题解决。
-
 下面讲一下间接光照技术。我们首先看一下传统的方法,一是Raytrace,还有一个Radiosity。我们方法是Point Cloud Bassd GI。最后讲一下基于点云的方法下,当场景很大,点云非常多导致显存放不下的大世界烘焙问题。
下面讲一下间接光照技术。我们首先看一下传统的方法,一是Raytrace,还有一个Radiosity。我们方法是Point Cloud Bassd GI。最后讲一下基于点云的方法下,当场景很大,点云非常多导致显存放不下的大世界烘焙问题。
-
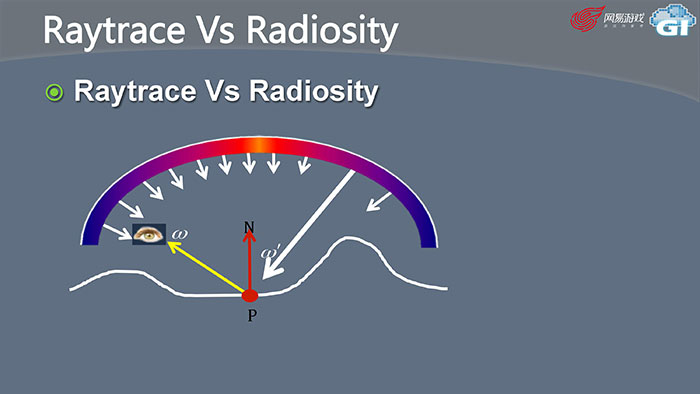 做间接光照为什么计算量大,因为我看到世界某一个位置,需要计算周围360度的光线入射进来的影响,根据材质算反射,需要对每一个入射光线进行同样的计算,这其实是一个递归的过程。
做间接光照为什么计算量大,因为我看到世界某一个位置,需要计算周围360度的光线入射进来的影响,根据材质算反射,需要对每一个入射光线进行同样的计算,这其实是一个递归的过程。
-
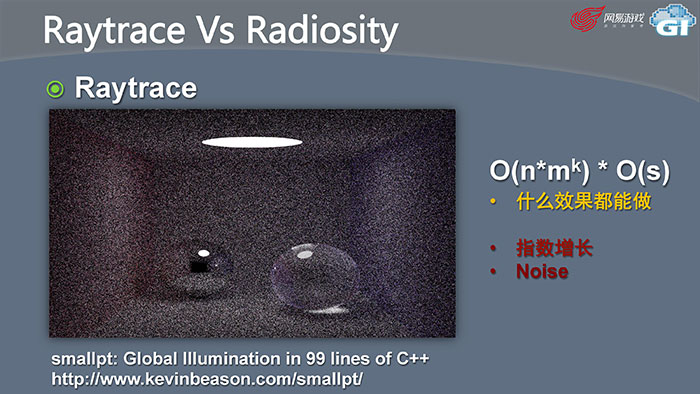 Raytrace就是这样的递归的递归。场景里每一个点,发射出N根光线,每一根光线碰到场景某一个点,又反射N根光线,直到有1根光线回到了光源,或者迭代层数到了我们设置的终止条件,然后结束返回,这个计算复杂度是
Raytrace就是这样的递归的递归。场景里每一个点,发射出N根光线,每一根光线碰到场景某一个点,又反射N根光线,直到有1根光线回到了光源,或者迭代层数到了我们设置的终止条件,然后结束返回,这个计算复杂度是 ,n是要计算的像素个数,m是采样的光线数量,k是迭代层数。O(s)是生成采样光线的一个固定开销。这样的好处是可以做任意效果,可以做高光的,也可以做其他的。但不足也很明显,计算量是呈指数增长的。而且如果采样光线不足,就会出现很严重的Noise。
,n是要计算的像素个数,m是采样的光线数量,k是迭代层数。O(s)是生成采样光线的一个固定开销。这样的好处是可以做任意效果,可以做高光的,也可以做其他的。但不足也很明显,计算量是呈指数增长的。而且如果采样光线不足,就会出现很严重的Noise。
-
 第二种方法叫辐射度,它的基本思路是不区分场景里的灯光与物体,把场景里所有的物体细分成一个个Surfel,类似于点云,每一个Surfel既是灯光又是被灯光照亮的物体。
第二种方法叫辐射度,它的基本思路是不区分场景里的灯光与物体,把场景里所有的物体细分成一个个Surfel,类似于点云,每一个Surfel既是灯光又是被灯光照亮的物体。
-
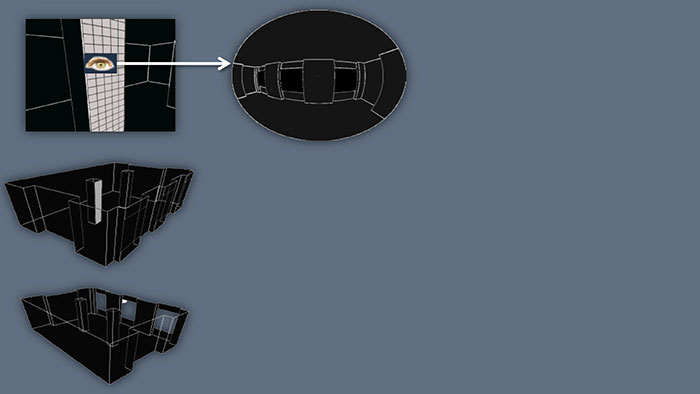 它的算法思路是什么样呢?假设场景是漆黑一片,外面有一个月亮,我们把场景里某个面剖分成很多小的细块,这些细块就是Surfel。检查其中一个Surfel是否被周围的场景打亮,这就相当于有一只眼睛贴在细块上面,顺着法线的方向去看,如果发现外面什么都看不到,那就说明这个点还是黑的。
它的算法思路是什么样呢?假设场景是漆黑一片,外面有一个月亮,我们把场景里某个面剖分成很多小的细块,这些细块就是Surfel。检查其中一个Surfel是否被周围的场景打亮,这就相当于有一只眼睛贴在细块上面,顺着法线的方向去看,如果发现外面什么都看不到,那就说明这个点还是黑的。
-
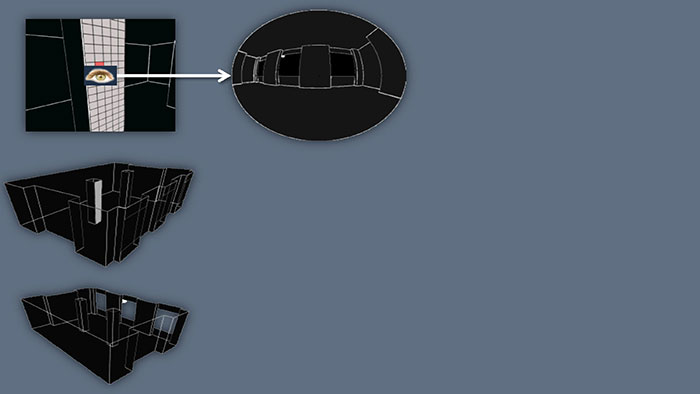 换下一个点,如果能看到外面的月亮,说明这里会被打亮。持续这个过程,就得到这个面的光照情况了。
换下一个点,如果能看到外面的月亮,说明这里会被打亮。持续这个过程,就得到这个面的光照情况了。
-
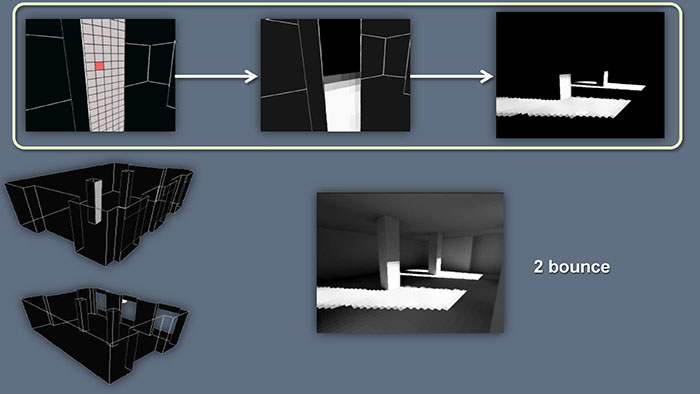 我们对整个场景所有的Surfel做这个处理,就得到了一次光照的迭代结果。
我们对整个场景所有的Surfel做这个处理,就得到了一次光照的迭代结果。
-
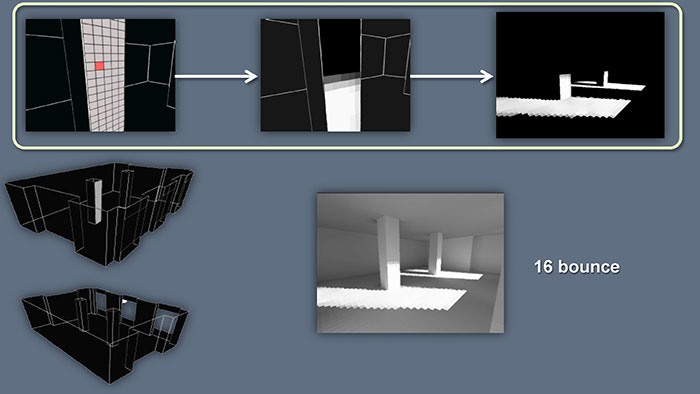 接着重复做这个过程,就得到了全部场景的光照情况。
接着重复做这个过程,就得到了全部场景的光照情况。
-
 这种方法的复杂度是O(n*n*k),n是Surfel的个数,k是光线迭代次数。它的优势在于计算量随反射次数线性增长不是指数增长,而且没有noise。但它的不足在于只能做漫反射的GI。另外我们可以看到阴影边缘是很严重的锯齿,这和Surfel精度有关,所以我们只用它来做间接光照。
这种方法的复杂度是O(n*n*k),n是Surfel的个数,k是光线迭代次数。它的优势在于计算量随反射次数线性增长不是指数增长,而且没有noise。但它的不足在于只能做漫反射的GI。另外我们可以看到阴影边缘是很严重的锯齿,这和Surfel精度有关,所以我们只用它来做间接光照。
-
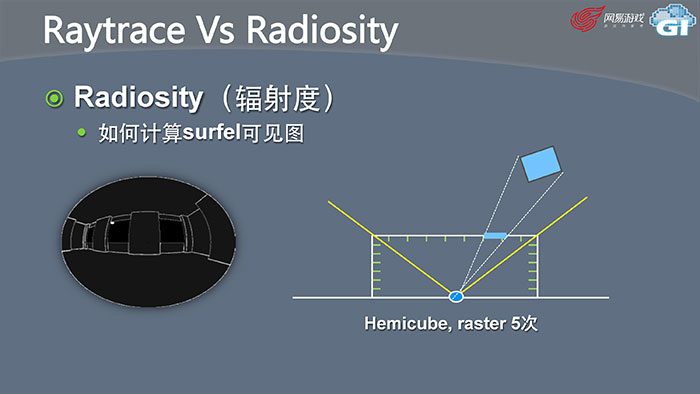 辐射度的方法有这样一个问题,怎样知道周围有哪些物体照亮了我?传统方法叫做Hemicube raster,对场景每个面进行一次光照化,虽然背面不需要,只用做5次这个过程,但依然非常耗资源。
辐射度的方法有这样一个问题,怎样知道周围有哪些物体照亮了我?传统方法叫做Hemicube raster,对场景每个面进行一次光照化,虽然背面不需要,只用做5次这个过程,但依然非常耗资源。
-
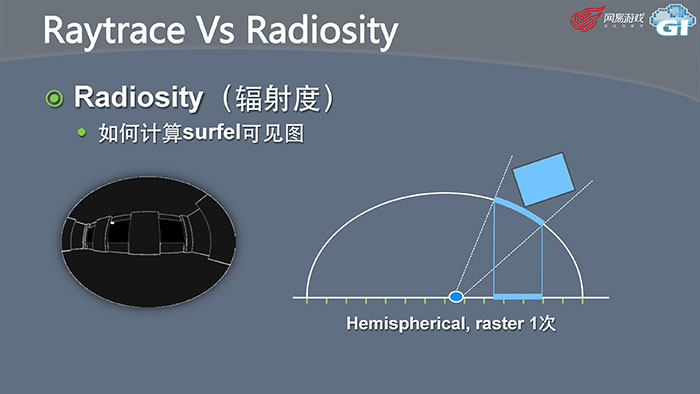 我们做的优化方法叫Hemispherical raster,我会把surfel投影到球面,把球面的东西再映射到平面上,这样只需要做一次,就完成了之前做5次的效果,效率上有所提升,而且精度刚好跟我们光照影响的精度一致,因为大家可以看到,沿着法线方向它的分配精度最高。
我们做的优化方法叫Hemispherical raster,我会把surfel投影到球面,把球面的东西再映射到平面上,这样只需要做一次,就完成了之前做5次的效果,效率上有所提升,而且精度刚好跟我们光照影响的精度一致,因为大家可以看到,沿着法线方向它的分配精度最高。
-
 最后看一下我们采用的Point Cloud based GI。它其实是基于辐射度方法的。主要参考了两篇论文,一个是电影渲染RenderMan中的全局光算法,一个是最快的Octree构建算法。Pixar算法比ray trace快4-10倍,它其实是CPU上面的集群渲染,我们把CPU的计算搬到GPU,用DX11+CUDA来做,就快了10-20倍。最后再对算法进行进一步优化,又能快10-20倍,全部叠加在一起就快了近1000倍。
最后看一下我们采用的Point Cloud based GI。它其实是基于辐射度方法的。主要参考了两篇论文,一个是电影渲染RenderMan中的全局光算法,一个是最快的Octree构建算法。Pixar算法比ray trace快4-10倍,它其实是CPU上面的集群渲染,我们把CPU的计算搬到GPU,用DX11+CUDA来做,就快了10-20倍。最后再对算法进行进一步优化,又能快10-20倍,全部叠加在一起就快了近1000倍。
-
 Point Cloud based GI算法分为三个步骤,第一个是点云生成,第二个是构建Octree,最后是计算间接光照。
Point Cloud based GI算法分为三个步骤,第一个是点云生成,第二个是构建Octree,最后是计算间接光照。
-
 点云要如何生成?我们用的方法和直接光照一样,因为我们有了每个模型不重叠的UV,所以可以直接在上面生成点云。
点云要如何生成?我们用的方法和直接光照一样,因为我们有了每个模型不重叠的UV,所以可以直接在上面生成点云。
-
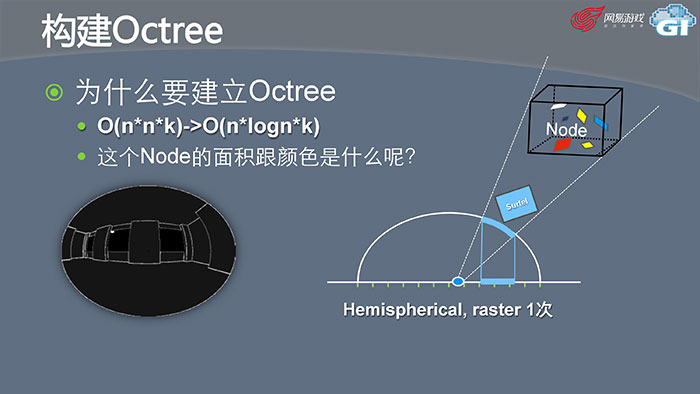 为什么要建立Octree(八叉树)?因为我们最初的辐射度算法复杂度是O(n*n*k),点云很多的情况下n2相对来说还是耗资源的,我们通过建立一个树的结构可以把复杂度降到O(n*log(n)*k)。如果是离的比较近的部分,我们就对Surfel进行光照化,如果是离得比较远的我们就对整个Node进行光照化,这样效率就会比较高。但这里有一个问题,如果是Surfel,面积和颜色都是已经记录下来的可以直接光照化。但是对于Node,因为里面存放了很多Surfel,它们的位置、朝向和颜色都不一样。对这样一个Node进行光照化,它的面积和颜色应该是什么呢?
为什么要建立Octree(八叉树)?因为我们最初的辐射度算法复杂度是O(n*n*k),点云很多的情况下n2相对来说还是耗资源的,我们通过建立一个树的结构可以把复杂度降到O(n*log(n)*k)。如果是离的比较近的部分,我们就对Surfel进行光照化,如果是离得比较远的我们就对整个Node进行光照化,这样效率就会比较高。但这里有一个问题,如果是Surfel,面积和颜色都是已经记录下来的可以直接光照化。但是对于Node,因为里面存放了很多Surfel,它们的位置、朝向和颜色都不一样。对这样一个Node进行光照化,它的面积和颜色应该是什么呢?
-
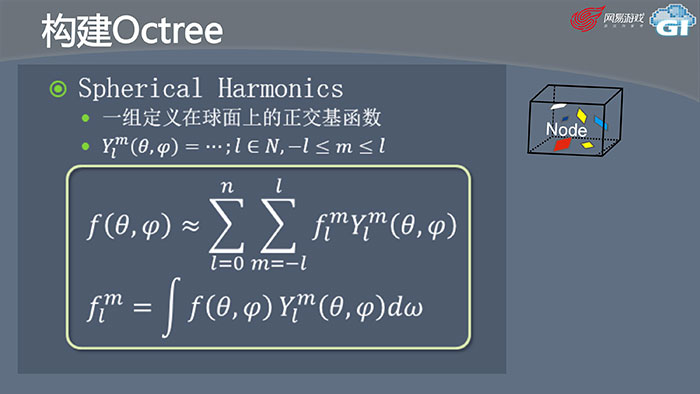 不得不介绍一些比较数学的东西,这里用到了球形函数,其实非常简单,就是一组定义在球面上的正交基函数。其主要作用是可以把一个任意球面上的函数近似地表达成几个参数相乘。那么这几个参数是怎么计算的呢?
不得不介绍一些比较数学的东西,这里用到了球形函数,其实非常简单,就是一组定义在球面上的正交基函数。其主要作用是可以把一个任意球面上的函数近似地表达成几个参数相乘。那么这几个参数是怎么计算的呢?
-
 我们用上面的公式计算这几个参数,有了这些参数后,我们就可以把一个函数变成几个参数,把两个函数的相加变成几个参数的相加。再看刚才的问题,Node的光照化面积是多少?首先把这些Surfel的面积转化为θ和φ的函数,这个函数就是自身的面积乘以dot(d,n),n是法向量,d是每个方向。得到参数后,我们可以算Node整体的每个方向的面积,把面积用θ和φ的函数表达。
我们用上面的公式计算这几个参数,有了这些参数后,我们就可以把一个函数变成几个参数,把两个函数的相加变成几个参数的相加。再看刚才的问题,Node的光照化面积是多少?首先把这些Surfel的面积转化为θ和φ的函数,这个函数就是自身的面积乘以dot(d,n),n是法向量,d是每个方向。得到参数后,我们可以算Node整体的每个方向的面积,把面积用θ和φ的函数表达。
-
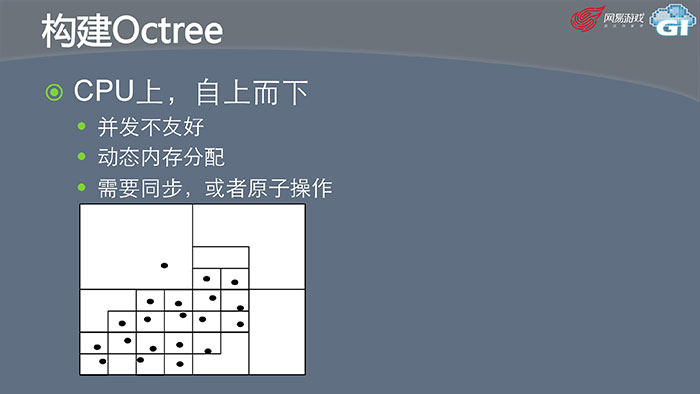 Octree在CPU上的构建是自上而下的。所有的节点放在里面,不满足需求就一分为八,然后考察每一个子节点,如果不满足需求就继续细分,直到每一个节点的个数满足需求。但这样有一些问题,首先因为是自上而下的算法,它不是并发友好的。而且是使用动态内存分配,还需要同步或者原子操作。
Octree在CPU上的构建是自上而下的。所有的节点放在里面,不满足需求就一分为八,然后考察每一个子节点,如果不满足需求就继续细分,直到每一个节点的个数满足需求。但这样有一些问题,首先因为是自上而下的算法,它不是并发友好的。而且是使用动态内存分配,还需要同步或者原子操作。
-
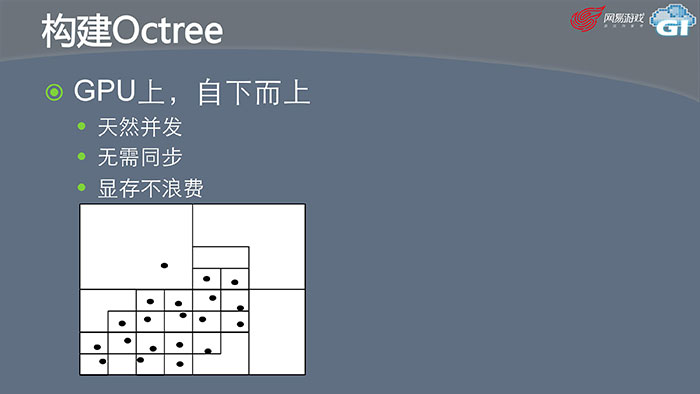 我们的算法是在GPU上自下而上的,会在最下面的节点先生成所有的Node,再往上递归,它是天然并发的。
我们的算法是在GPU上自下而上的,会在最下面的节点先生成所有的Node,再往上递归,它是天然并发的。
-
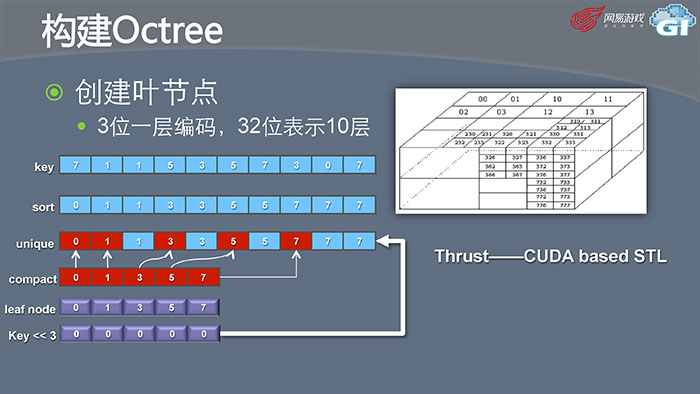 我们直接看算法,首先需要对每个Surfel进行编码。一个八叉树一层是8个节点,可以用3个比特表示它在节点中的位置,用32位就可以表达10层。首先确定这个八叉树需要几层,再算每个Surfel在叶节点的时候需要的key是多少,相同的key在同一个节点里。算好了key就对它进行排序,这时候0就应该是一个节点,1也应该是一个节点,再把不同的地方表达出来,用compact把所有不同的值放进一个数组,这个数组中的五个数字就是我们的叶节点,这样Leaf Node就算出来了。然后再把key左移3位,变成上一层节点,再重复这个过程,就创建出了上一层节点,直到我们算到Root Node为止。左边如unique、compact等都是STL的标准算法,CUDA已经可以帮我们实现了。
我们直接看算法,首先需要对每个Surfel进行编码。一个八叉树一层是8个节点,可以用3个比特表示它在节点中的位置,用32位就可以表达10层。首先确定这个八叉树需要几层,再算每个Surfel在叶节点的时候需要的key是多少,相同的key在同一个节点里。算好了key就对它进行排序,这时候0就应该是一个节点,1也应该是一个节点,再把不同的地方表达出来,用compact把所有不同的值放进一个数组,这个数组中的五个数字就是我们的叶节点,这样Leaf Node就算出来了。然后再把key左移3位,变成上一层节点,再重复这个过程,就创建出了上一层节点,直到我们算到Root Node为止。左边如unique、compact等都是STL的标准算法,CUDA已经可以帮我们实现了。
-
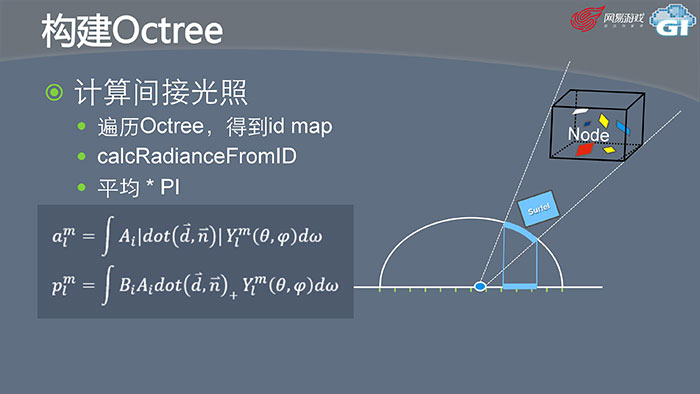 当我们有了Octree和Surfel之后再计算间接光照时,遍历Octree,得到id map。根据id map上面记录的Surfel和Node去推算间接光照的强度。在程序里面就是calcRadianceFromID这个函数,拿到这个值以后再求出平均值乘以PI。
当我们有了Octree和Surfel之后再计算间接光照时,遍历Octree,得到id map。根据id map上面记录的Surfel和Node去推算间接光照的强度。在程序里面就是calcRadianceFromID这个函数,拿到这个值以后再求出平均值乘以PI。
-
 做完这些后,发现烘焙一个产品依然需要10分钟的时间,还是超过我们的预期。后来发现我们把烘焙精度和间接光照的精度等同起来了,因为我们是超采样的,1张超采样的Light Map就有1600W的点云,数量太大。所以我们把烘焙精度和间接光照精度分离开,间接光照在一个比较低的精度上做,烘焙则在超采样上面做。
做完这些后,发现烘焙一个产品依然需要10分钟的时间,还是超过我们的预期。后来发现我们把烘焙精度和间接光照的精度等同起来了,因为我们是超采样的,1张超采样的Light Map就有1600W的点云,数量太大。所以我们把烘焙精度和间接光照精度分离开,间接光照在一个比较低的精度上做,烘焙则在超采样上面做。
-
 下面说我们怎么解决大世界的问题,因为1000W点云需要400M的显存,所以如果我们有一个1000米×1000米的正方形,就需要4G显存,这对显存的开销要求太高了,所以分块烘焙是必须的。把场景分成均匀的块,每一个块进行一次烘焙,烘焙这些块的时候考虑周围围绕的九个块。不过这个方法有很多弊端,可能块很难划分,如果划分太大,就没有意义;如果划分太小,可能对烘焙产生主要影响的因素在块的外面。所以我们用另一个方法,对整个场景建立粗糙的点云,然后对每一个块以及每个块扩展出的一点安全区做精细点云,再把这两个结合在一起,由于离得远的地方进行光照化的时候都变成一个Node了,所以即使是粗糙的点云也不会影响最终的效果。
下面说我们怎么解决大世界的问题,因为1000W点云需要400M的显存,所以如果我们有一个1000米×1000米的正方形,就需要4G显存,这对显存的开销要求太高了,所以分块烘焙是必须的。把场景分成均匀的块,每一个块进行一次烘焙,烘焙这些块的时候考虑周围围绕的九个块。不过这个方法有很多弊端,可能块很难划分,如果划分太大,就没有意义;如果划分太小,可能对烘焙产生主要影响的因素在块的外面。所以我们用另一个方法,对整个场景建立粗糙的点云,然后对每一个块以及每个块扩展出的一点安全区做精细点云,再把这两个结合在一起,由于离得远的地方进行光照化的时候都变成一个Node了,所以即使是粗糙的点云也不会影响最终的效果。
-
 最后简单总结一下今天讲的内容:
最后简单总结一下今天讲的内容:
1. 烘焙基本是所有3D手游的选择;
2. CloudGI比Cpu raytrace快1000倍,并且贴合手机网游的实际需求;而且由于我们使用有机代码,很方便优化,还可以自己写一个shader对材质进行自定义。
3. 用Octree来加速的类Sadiosity算法,另外我们分离了烘焙的精度和间接光照的精度;
4. 用分块烘焙的方法解决显存问题;
5. 用动态点云解决动态物体的光照问题。
-
 我的分享到此结束,谢谢。
我的分享到此结束,谢谢。