藏书馆
欢迎来到网易游戏学院藏书馆
protobuf python版的改造
googleprotobuf是google的一个开源库,使用它可以自己定义数据结构并且生成读写代码。这个库有两个实现版本:c++和python,c++版本实现的比较完美,但是python版中有许多不方便的地方,本文主旨是介绍我们项目中对python版的改造。
googleprotobuf是google的一个开源库,使用它可以自己定义数据结构并且生成读写代码。这个库有两个实现版本:c++和python,c++版本实现的比较完美,但是python版中有许多不方便的地方。这个库应该很多同学都有了解,这里不会介绍这个库的用法,本文主旨是介绍我们项目中对python版的改造,改造的主要目的是解决使用方便性问题,这些改造已经应用在实际线上,是确定没有问题的。本文针对的是protobuf2.5.0,在2.4.1中也同样测试过,没有问题。
一、纯python版,unicode问题
我们系统中的内码是统一UTF-8的,但是protobuf中的内码是unicode的,会造成问题重现方式如下:
1.现有以下数据定义:
message UnitProto {
required string name=1;
}
用python版的protobuf生成相应的读写格式。
2.使用这个proto读取一个文本,文本内容很简单:“name:'怪物'”。
3.假设有一个客户端消息,这个消息是用c++版的protobuf生成的,这个消息内容是:
message SMSG_UnitInfo {
required string name=1;
}
问题会出现在,当我们把pythonprotobuf实现的UnitProto对象的name字段赋值给c++protobuf实现的SMSG_UnitInfo对象的name字段时,伪代码即SMSG_UnitInfo.name=UnitProto.name,python会提示编码错误的trace,不能把XXX字节转换为目标编码,原因是UnitProto.name字段是一个Unicode。假如我们想把一个中文字符“你好”赋值给UnitProto.name,也是不行的,我们必须把unicode版本的u“你好”赋值给它。
可能会有人问道,为什么要两个版本protobuf混用?原因是因为效率问题,在发封包上我们必须用c++版的protobuf。纯python版的protobuf的SerializeToString操作效率比c++版本低10倍,下图是一次Serialize玩家数据时间对比:
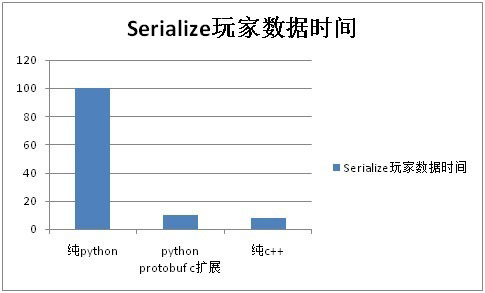 |
并且我们具体测试过,用纯python版protobuf,一个map_server的CPU会上升5%左右;在数据读取上,因为数据时给游戏逻辑用的,游戏逻辑是python的,用python版protobuf最方便,否则会相当麻烦。
修改方式是:
1.python/google/protobuf/internal/type_checkers.py中,CheckValue函数是用来检查string类型赋值的,把“Ifthevalueisoftype'str'makesurethatitisin7-bitASCIIencoding”注释之后的全部去掉,这段的意思是当我们把utf8类型(即python的str类型)赋值给它时,它会首先尝试转unicode,这个是不需要的。
2.python/google/protobuf中的text_format.py文件和和internal中的api_implementation.py等7个文件中,都有尝试unicode或者utf-8转换操作,这些操作可以全部去掉。
3.修改google/protobuf/compiler/python/python_generator.cc,这个是编译生成protoc的问题,protoc是编译.proto文件到源代码的程序。如果是string类型,默认生成的pythonprotobuf代码中,会把这个string赋值为unicode的空字符串。在这个文件中找到unicode关键字,去掉,改成空字符串即可。
这么修改完后,不仅效率会提升,而且再也不用考虑unicode问题。
二、protobufc扩展,unicode问题
protobufc扩展是pythonprotobuf底层用c实现,这样的话,python很慢的SerializeToString操作效率会大大提升。我们系统在收发客户端封包上,使用了c扩展来解析。但是使用它的过程也很坎坷。
首先我们碰到的还是unicode问题,出现原因和上面的方式一摸一样,我们对它的修改是:修改代码python/google/protobuf/pyext/python-proto2.ccCheckAndSetString这个函数,如果PyString_Check成功的话,不要让它尝试转unicode,直接当bytes类型使用。
三、protobufc扩展,crash问题
protobufc扩展实现得比较简单,是代理模式的,即对于每一个c++对象,都有一个相应的python对象为止服务,所以会引发这个问题:
假设有如下消息
1 message PlayerData {
2 required uint64 guid=1;
3 }
4 message PlayerMessage {
5 required PlayerData player=1;
6 }
在python中,收到PlayerMessage消息,然后把PlayerData消息保存起来,但是没有保存PlayerMessage消息,那么就 会crash。
原因是python/google/protobuf/pyext/python-proto2.cc中,CMessageDealloc释放函数的实现:
1 static void CMessageDealloc(CMessage* self) {
2 if (self->free_message) {
3 if (self->read_only) {
4 PyErr_WriteUnraisable(reinterpret_cast
5 }
6 delete self->message;
7 }
8 self->ob_type->tp_free(reinterpret_cast
9 }
如果是根节点,那么free_message是true的,就会delete这个消息,而delete的同时,所有子节点消息都被delete了,然后如果再使用子节点消息,那么就是野指针了,这个问题用图表示如下:
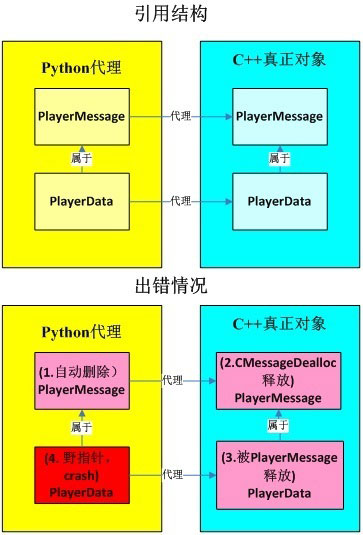 |
这个问题的根本原因是:python是用引用计数,自动管理内存的,而c++是手动管理的。如果c++的protobuf能够增加选项:当delete父消息的时候,不要同时delete子消息,然后由python的c++扩展来做,这样就可以。我们没有做这一步,这个改造在计划中。我们做的是,限制c++扩展的使用,只在收发客户端消息的时候使用,因为我们在收发客户端消息的时候不会保存任何封包对象。但是这就引发了后面的一个protobuf机制问题。
四、protobufc扩展,兼容问题
根据文档中的说的,要启用protobufc扩展的方法是设置PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION环境变量,那就是说,要么只能全部启用c扩展,要么只能全部不启用,不能动态判定。这个不满足我们的要求,我们要求对于某些封包是使用c扩展的,而另外一些不使用。我们尝试过很多种方式来改变这个,也失败过好多次,这个最麻烦的是,假设一个文件是c扩展的,那么它引用的所有子文件也必须是c扩展的,所以只能生成两份代码。所以我们的最终方案是:protoc生成代码的时候,生成两份proto代码,具体做法如下:
protoc源代码google/protobuf/compiler/python/python_generator.cc中,增加一个pyext选项,protoc的执行命令行改为:protoc--proto_path=./--proto_path=./--python_out=pyext:./client_package2.proto,这里面--python_out=pyext:./这种格式是已有的只是对pyext加了另外的解释。从只会生成一份python的_pb2.py文件改成会额外再生成一个_pyext.py文件,这两份文件的不同点是:pyext文件引用的所有模块都是pyext后缀的,DESCRIPTOR中的扩展字段是PYEXT_TYPE='pyext',FieldDescriptor的描述符中也会写明PYEXT_TYPE='pyext' 在python/google/protobuf/reflection.py和python/google/protobuf/descriptor.py中全部加上判定,如果使用pyext,那么就new和引用c扩展类型的文件
做完之后,我们只需要引用不同的模块,就会用上纯pythonprotobuf或者是c扩展的protobuf。但是有一个局限:在python应用上,对于同样一个名称的类,比如PlayerData,假如一个是纯python的,一个是c扩展的,它们是不能互相CopyFrom的,代码示例如下:
pydata= PlayerData_pb2.PlayerData()
pyextdata= PlayerData_pyext.PlayerData()
pydata.CopyFrom(pyextdata)
这样会报类型错误,必须这么做:pydata.ParseFromString(pyextdata.SerializeToString()),我们测试过,ParseFromString+SerializeToString的速度比CopyFrom慢5倍。所以我们要尽量使用CopyFrom,但是又要保证不track。虽然这个示例表示得很清楚,但是由于python是无类型的,层层包装后,这个错误会有些头大。
五、protobufc扩展解引用
我们发现所有protobufc扩展的对象,都不会自动释放,必须要被python的gc释放,究其原因,有两个:
对于父子类型或者repeated类型的字段,父必须包含子,而子又要有父的引用,所以循环引用了。我们尝试过用weak_ptr来解决这种引用问题,但是发现weak_ptr不支持python的c扩展类型。而且,如果我们解决了这个问题,我们会重新面临上面的“pythonc扩展,crash问题”中的父子释放问题。所以这个问题暂时无解。
对于没有repeated字段或者父子引用的简单消息,protobuf强制加引用了,代码在python/google/protobuf/internal/cpp_message.py的Init函数中
1 if message_descriptor.is_extendable:
2 self.Extensions = ExtensionDict(self)
3 else:
4 # Reference counting in the C++ code is broken and depends on
5 # the Extensions reference to keep this object alive during unit
6 # tests (see b/4856052). Remove this once b/4945904 is fixed.
7 self._HACK_REFCOUNTS = self
8 pass
第二点是可以改的,我们注释了#self._HACK_REFCOUNTS=self,经实际测试,没有问题,对于简单proto对象是可以自动回收的,不需要经过gc。
六、protobufc扩展效率提升
在c扩展的SerializeToString实现中有判定这个封包是否IsInitialized。IsInitialized中会遍历每一个字段检查,比较耗时,所以我们去掉了这个判定,我们检查了以下三个版本的protobuf代码:c++版protobuf,c扩展protobuf,纯pythonprotobuf,发现只有c扩展的有检查这个字段,所以我们在python/google/protobuf/internal/cpp_message.py中的SerializeToString函数中,注释掉了IsInitialized判定。
至此,我们的protobuf改造初步可用,现在还剩一个问题在解决:一个玩家从一台服务器转移去另外一台,会触发序列化/反序列化,这个操作是纯pythonprotobuf来操作的,一个玩家需要50ms。就是说,一场10v10的战斗,仅仅转移的时间就需要50*20=1000ms,也就是1秒时间。我们现在想解决的问题就是尽量全部用c扩展的protobuf,但是又要保证服务器不因为父子删除而crash。