藏书馆
欢迎来到网易游戏学堂藏书馆
LINUX MALLOC 2:TCMALLOC
作者:桂神(程序)
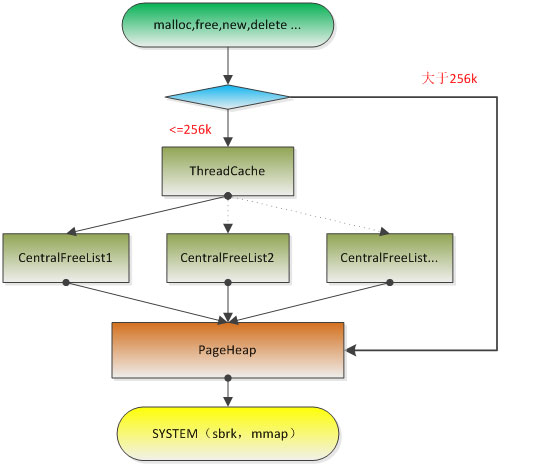
tcmalloc是与glibc malloc同级的一套内存管理库,tcmalloc会hack所有的glibc提供的接口,为调用者提供透明的内存分配。tcmalloc工作流程如下,我们从底往上叙述:
const size_t kPageShift = 13;
const size_t kPageSize = 1 < < kPageShift;
对于一个指针p,p > >kPageShift即是p的页地址。同样的对于一个页地址x,管理的实际内存区间是[x <
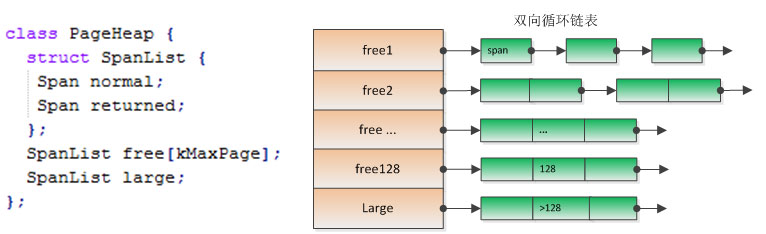
normal和returned是两种不同类型的Span,分别对应Span->location的ON_NORMAL_FREELIST和ON_RETURNED_FREELIST,稍后会详细介绍。kMaxPages = 1 << (20-kPageShift)=128,即length<=kMaxPage(1MB)的Span保存在free数组中,大于1MB的Span全都保存在large中,这样可以尽量保证小块内存申请的速度,而又不至于维护太多的链表。
PageHeap主要提供以下两个接口:
1、Span* New(Length n); // 申请n个页的Span
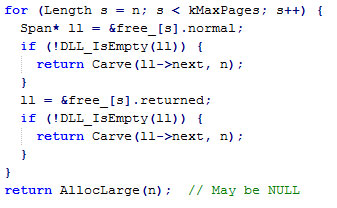
首先在free[n,128]中查找、然后到large中查找,目标就是在所有的链表中找到一个最小的满足要求的Span,优先使用normal类链表中的Span。如果找到了一个Span,则尝试分裂(Carve)这个Span并分配出去;如果所有的链表中都没找到length>=n的Span,则向系统申请内存。Tcmalloc一次最少向系统申请1MB的内存,默认情况下,使用sbrk申请,在sbrk失败的时候,使用mmap申请。
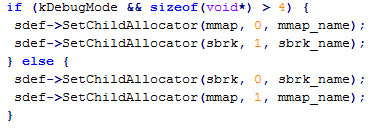
可以看到只有在64位系统的debug模式上才会使用相反的顺序申请。把从系统申请的内存通过Delete接口保存到PageHeap中,然后重新尝试申请操作。
2、void Delete(Span* span); // 释放一个Span
释放的时候需要考虑Span能否合并,以减少碎片的产生。对于64位系统,内存地址的实际有效位是48位(26万G,足够满足需求),所以有效的页地址是48-kPageShifit = 35位。PageHeap使用3级的RadixTree记录所有的页。
RadixTree
对于一个Span只需要在RadixTree中记录start, start+length-1两个点,即:
p[span->start] = span;
p[span->start + span->length-1] = span;
可以查找start-1即可得到前一个Span,查找start+length得到后一个Span。根据前后Span的状态(location)决定是否可以合并,合并的操作也非常简单,例如合并前一个Span *prev:
(1)把prev从链表中移除。
(2)span->start = prev->start;
span->length += prev->length;
把合并后的span保存到链表和RadixTree中。
当空闲的页数足够多的时候,还要考虑归还内存到系统,默认情况下,平均释放1000个Page到PageHeap中,会释放1个Page给系统。这里是调用madvise通知系统Span所在的物理内存可以回收,并把释放之后的Span插入到对应的returned链表中。如果分配到returned链表中的Span,系统会重新给这块地址分配物理内存。
对于释放内存给系统,这里只考虑释放的页数,例如频繁的申请/释放1个page,当第1000次释放的时候,就可能会归还给系统,并不是系统中空闲页数是1000的时候,才释放一个页给系统。
当我们申请的内存大于kMaxSize(256k)的时候,tcmalloc直接向全局的PageHeap中申请最小的Span分配出去(return span->start << kPageShift));当申请的内存小等于kMaxSize的时候,则使用以下方式分配。为了叙述方便,我们把>kMaxSize的内存称为大内存,把<=kMaxSize的内存称为小内存。
例如:申请的大小size=33,实际会分配48;size=150,实际分配160。
size_t psize = kPageSize;
while (psize % size > psize/8)) {
psize += kPageSize;
}
int num = 64 * 1024.0 / size;
if (num < 2) num = 2;
if (num > 32) num = 32;
太少会频繁lock CentralFreeList,太多会在ThreadCache中缓存过多的内存对象,造成浪费。
例如:
char s[64]是我们可以分配的内存空间,每次只申请8Byte,这样我们可以把s[64]分成8份,可以使用一个链表来管理s[64]:

初始情况下:s[0-7]保存s[8]的地址,s[8-15]保存s[16]的地址,s[56-63]保存一个NULL指针。使用这种链表的最大好处是节省内存,自己管理自己。
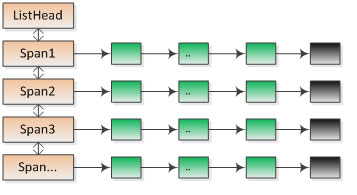
Span使用上文介绍的单项链表管理小块内存:
struct Span {
void *objects; // 单向链表表头
uint refcount; // 分配出去内存的个数
};
初始化过程:

从Span中取得一个内存对象:

释放一个内存对象到Span中:

class CentralFreeList {
Span empty_; // 已经用完的Span (Span->object == NULL)
Span nonempty_; // 没有用完的Span。
int RemoveRange(void **start, void **end, int N); // 申请N个内存。
void InsertRange(void *start, void *end, int N); // 释放N个内存。
};
申请过程:首先从链表nonempty中的Span中获取对象,如果nonempty中的Span空闲对象不够,则从PageHeap中申请新的Span加入到noempty连表中。如果Span的内存已经用完(span->object == NULL),则把这个Span移到empty链表中。
对于被CentralFreeList使用Span,会把这个Span上的所有页都注册到RadixTree中,这样对于这个span上的任意一个小对象,都可以通过页ID(p >> kPageShift)找到这个Span。
释放过程:把内存对象依次保存到相应的Span中。如果Span在empty链表中,则移到noempty链表中,如果Span的内存已经完全被释放(span->refcount == 0),则把这个Span归还到PageHeap中。
ThreadCache为每种类型的内存都保存了一个单项链表:
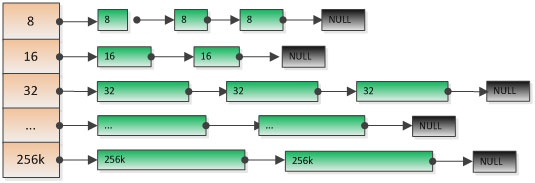
申请内存的时候,首先计算出对应的内存类型cl,然后从list [cl]中pop内存。当list [cl]为空的时候,会尝试向对应全局的CentralFreeList中取内存对象,放到链表list [cl]里。
释放内存的时候,首先会找到当前线程的ThreadCache,计算出释放的内存对应的内存类型cl,保存到list[cl]中。需要指出的是在线程A中申请的内存,在线程B中释放是没有问题的。ThreadCache只是一个缓存,用来减少锁CenterFreeList的次数。
2.对于大于1024的内存tcmalloc申请更快,因为是一一对应的。
3.tcmalloc向系统申请内存的接口统一使用sbrk,而malloc则会在内存较大和非main_arena的线程中使用mmap,也就是说malloc不同的线程(arena)的内存是不能合并的。
4.标准接口:tcmalloc提供了所有glibc所提供的内存申请、释放接口,但是由于实现算法完全不同,部分统计接口及内容有所改动。
5.官网有详细的效率评测和使用方法介绍,实际的效果,最好是把tcmalloc编译到自己项目中对比。因为所有接口对用户透明,所以这里代价很小。
tcmalloc是与glibc malloc同级的一套内存管理库,tcmalloc会hack所有的glibc提供的接口,为调用者提供透明的内存分配。tcmalloc工作流程如下,我们从底往上叙述:
一、PageHeap
tcmalloc把8kb的连续内存称为一个页(Page),可以用下面两个常量来描述:const size_t kPageShift = 13;
const size_t kPageSize = 1 < < kPageShift;
对于一个指针p,p > >kPageShift即是p的页地址。同样的对于一个页地址x,管理的实际内存区间是[x <
对于一个Span,管理的实际内存区间是[start << kPageShift, (start+length)<
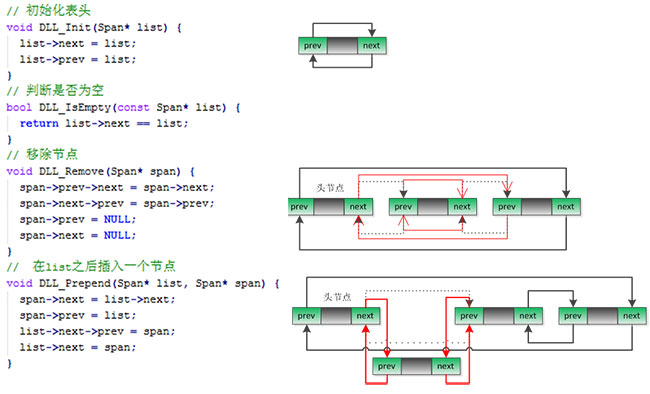
PageHeap的结构如下:PageHeap主要提供以下两个接口:
1、Span* New(Length n); // 申请n个页的Span
2、void Delete(Span* span); // 释放一个Span
释放的时候需要考虑Span能否合并,以减少碎片的产生。对于64位系统,内存地址的实际有效位是48位(26万G,足够满足需求),所以有效的页地址是48-kPageShifit = 35位。PageHeap使用3级的RadixTree记录所有的页。
RadixTree
最坏情况下,我们使用Span* p[1 << 35] 即可记录所有的页所属的Span。RadixTree就是把数组分级,即:Span *p[1<<12][1<<12][1<<11]。对于第一级的p[1<<12],在大部分情况下2、3级是空的,如p[1000]在未被使用的情况下不需要申请之后的[1<<12][1<<11],同样的p[1000][1000]在未被使用的情况下不需要申请最后的一级[1<<11]。RadixTree就是类似的空间优化版的多级数组,在需要的时候再申请下一级的内存。这在处理连续地址时十分高效。

为了叙述方便下文使用Span* p[1<<35]表示RadixTree。对于一个Span只需要在RadixTree中记录start, start+length-1两个点,即:
p[span->start] = span;
p[span->start + span->length-1] = span;
可以查找start-1即可得到前一个Span,查找start+length得到后一个Span。根据前后Span的状态(location)决定是否可以合并,合并的操作也非常简单,例如合并前一个Span *prev:
(1)把prev从链表中移除。
(2)span->start = prev->start;
span->length += prev->length;
把合并后的span保存到链表和RadixTree中。
当空闲的页数足够多的时候,还要考虑归还内存到系统,默认情况下,平均释放1000个Page到PageHeap中,会释放1个Page给系统。这里是调用madvise通知系统Span所在的物理内存可以回收,并把释放之后的Span插入到对应的returned链表中。如果分配到returned链表中的Span,系统会重新给这块地址分配物理内存。
对于释放内存给系统,这里只考虑释放的页数,例如频繁的申请/释放1个page,当第1000次释放的时候,就可能会归还给系统,并不是系统中空闲页数是1000的时候,才释放一个页给系统。
当我们申请的内存大于kMaxSize(256k)的时候,tcmalloc直接向全局的PageHeap中申请最小的Span分配出去(return span->start << kPageShift));当申请的内存小等于kMaxSize的时候,则使用以下方式分配。为了叙述方便,我们把>kMaxSize的内存称为大内存,把<=kMaxSize的内存称为小内存。
二、SizeMap
tcmalloc把<=256k的内存分成kNumClasses(86)类,其中每种类型的内存有以下属性:大小(size)、页数(pages)、移动个数。这些常量会在tcmalloc初始化的时候计算好,保存到常量类SizeMap中。1、大小(size)
使用以下规则算出:
8,16,32,48,64,80,96,112,128,144,160,…,1024,1152,1280,…, 262144例如:申请的大小size=33,实际会分配48;size=150,实际分配160。
2、页数
每一种类型的小内存,都保存在一个对应的全局的CentralFreeList对象中。所有小内存的申请,最后都是向CentralFreeList申请,而CentralFreeList则向PageHeap中申请内存。 CentralFreeList每次会固定的向PageHeap申请x页,保证使得浪费的空间低于1/8。size_t psize = kPageSize;
while (psize % size > psize/8)) {
psize += kPageSize;
}
3、移动个数num_objects_to_move
在多线程情况下,如果每个线程都从CentralFreeList中申请内存,就会频繁的lock CentralFreeList,大量的时间浪费在锁等待上。为了解决这种情况,tcmalloc会为每个线程都保存了一个ThreadCache类对象,num_objects_to_move即是ThreadCache每次从CentralFreeList中取得内存的个数。通过如下规则算出:int num = 64 * 1024.0 / size;
if (num < 2) num = 2;
if (num > 32) num = 32;
太少会频繁lock CentralFreeList,太多会在ThreadCache中缓存过多的内存对象,造成浪费。
三、单向链表
在介绍ThreadCache之前,我们先介绍一种内存管理算法中常用的一种数据结构:单向链表例如:
char s[64]是我们可以分配的内存空间,每次只申请8Byte,这样我们可以把s[64]分成8份,可以使用一个链表来管理s[64]:
初始情况下:s[0-7]保存s[8]的地址,s[8-15]保存s[16]的地址,s[56-63]保存一个NULL指针。使用这种链表的最大好处是节省内存,自己管理自己。
四、CentralFreeList
tcmalloc为每种类型的内存都保存了一份全局的CentralFreeList对象,CentralFreeList负责从PageHeap申请Span,并且给ThreadCache提供内存申请。
struct Span {
void *objects; // 单向链表表头
uint refcount; // 分配出去内存的个数
};
初始化过程:
Span empty_; // 已经用完的Span (Span->object == NULL)
Span nonempty_; // 没有用完的Span。
int RemoveRange(void **start, void **end, int N); // 申请N个内存。
void InsertRange(void *start, void *end, int N); // 释放N个内存。
};
申请过程:首先从链表nonempty中的Span中获取对象,如果nonempty中的Span空闲对象不够,则从PageHeap中申请新的Span加入到noempty连表中。如果Span的内存已经用完(span->object == NULL),则把这个Span移到empty链表中。
对于被CentralFreeList使用Span,会把这个Span上的所有页都注册到RadixTree中,这样对于这个span上的任意一个小对象,都可以通过页ID(p >> kPageShift)找到这个Span。
释放过程:把内存对象依次保存到相应的Span中。如果Span在empty链表中,则移到noempty链表中,如果Span的内存已经完全被释放(span->refcount == 0),则把这个Span归还到PageHeap中。
五、ThreadCache
我们所有申请的小内存,都是从ThreadCache中申请。tcmalloc为每个线程创建一个ThreadCache对象,当线程结束的时候,ThreadCache对象会随之销毁。linux实现中使用到了pthread库的几个API:pthread_key_create,pthread_getspecific,pthread_setspecific,具体实现不再赘述。ThreadCache为每种类型的内存都保存了一个单项链表:
释放内存的时候,首先会找到当前线程的ThreadCache,计算出释放的内存对应的内存类型cl,保存到list[cl]中。需要指出的是在线程A中申请的内存,在线程B中释放是没有问题的。ThreadCache只是一个缓存,用来减少锁CenterFreeList的次数。
六、与GLIBC MALLOC的对比
1.大多数情况下,tcmalloc要比malloc更占用内存。2.对于大于1024的内存tcmalloc申请更快,因为是一一对应的。
3.tcmalloc向系统申请内存的接口统一使用sbrk,而malloc则会在内存较大和非main_arena的线程中使用mmap,也就是说malloc不同的线程(arena)的内存是不能合并的。
4.标准接口:tcmalloc提供了所有glibc所提供的内存申请、释放接口,但是由于实现算法完全不同,部分统计接口及内容有所改动。
5.官网有详细的效率评测和使用方法介绍,实际的效果,最好是把tcmalloc编译到自己项目中对比。因为所有接口对用户透明,所以这里代价很小。